Introduction
In parallel with this chapter, you should read Chapter 20 of Thomas Connolly and Carolyn Begg, "Database Systems A Practical Approach to Design, Implementation, and Management", (5th edn.).
The purpose of this chapter is to introduce the fundamental technique of concurrency control, which provides database systems with the ability to handle many users accessing data simultaneously. In addition, this chapter helps you understand the functionality of database management systems, with special reference to online transaction processing (OLTP). The chapter also describes the problems that arise out of the fact that users wish to query and update stored data at the same time, and the approaches developed to address these problems, together with their respective strengths and weaknesses in a range of practical situations.
There are a number of concepts that are technical and unfamiliar. You will be expected to be able to handle these concepts but not to have any knowledge of the detailed algorithms involved. This chapter fits closely with the one on backup and recovery, so you may want to revisit this chapter later in the course to review the concepts. It will become clear from the information on concurrency control that there are a number of circumstances where recovery procedures may need to be invoked to salvage previous or currently executing transactions. The material covered here will be further extended in the chapter on distributed database systems, where we shall see how effective concurrency control can be implemented across a computer network.
Context
Many criteria can be used to classify DBMSs, one of which is the number of users supported by the system. Single-user systems support only one user at a time and are mostly used with personal computers. Multi-user systems, which include the majority of DBMSs, support many users concurrently.
In this chapter, we will discuss the concurrency control problem, which occurs when multiple transactions submitted by various users interfere with one another in a way that produces incorrect results. We will start the chapter by introducing some basic concepts of transaction processing. Why concurrency control and recovery are necessary in a database system is then discussed. The concept of an atomic transaction and additional concepts related to transaction processing in database systems are introduced. The concepts of atomicity, consistency, isolation and durability – the so-called ACID properties that are considered desirable in transactions - are presented.
The concept of schedules of executing transactions and characterising the recoverability of schedules is introduced, with a detailed discussion of the concept of serialisability of concurrent transaction executions, which can be used to define correct execution sequences of concurrent transactions.
We will also discuss recovery from transaction failures. A number of concurrency control techniques that are used to ensure noninterference or isolation of concurrently executing transactions are discussed. Most of these techniques ensure serialisability of schedules, using protocols or sets of rules that guarantee serialisability. One important set of protocols employs the technique of locking data items, to prevent multiple transactions from accessing the items concurrently. Another set of concurrency control protocols use transaction timestamps. A timestamp is a unique identifier for each transaction generated by the system. Concurrency control protocols that use locking and timestamp ordering to ensure serialisability are both discussed in this chapter.
An overview of recovery techniques will be presented in a separate chapter.
Concurrent access to data
Concept of transaction
The first concept that we introduce to you in this chapter is a transaction. A transaction is the execution of a program that accesses or changes the contents of a database. It is a logical unit of work (LUW) on the database that is either completed in its entirety (COMMIT) or not done at all. In the latter case, the transaction has to clean up its own mess, known as ROLLBACK. A transaction could be an entire program, a portion of a program or a single command.
The concept of a transaction is inherently about organising functions to manage data. A transaction may be distributed (available on different physical systems or organised into different logical subsystems) and/or use data concurrently with multiple users for different purposes.
Online transaction processing (OLTP) systems support a large number of concurrent transactions without imposing excessive delays.
Transaction states and additional operations
For recovery purposes, a system always keeps track of when a transaction starts, terminates, and commits or aborts. Hence, the recovery manager keeps track of the following transaction states and operations:
- BEGIN_TRANSTRACTION: This marks the beginning of transaction execution.
- READ or WRITE: These specify read or write operations on the database items that are executed as part of a transaction.
- END_TRANSTRACTION: This specifies that read and write operations have ended and marks the end limit of transaction execution. However, at this point it may be necessary to check whether the changes introduced by the transaction can be permanently applied to the database (committed) or whether the transaction has to be aborted because it violates concurrency control, or for some other reason (rollback).
- COMMIT_TRANSTRACTION: This signals a successful end of the transaction so that any changes (updates) executed by the transaction can be safely committed to the database and will not be undone.
- ROLLBACK (or ABORT): This signals the transaction has ended unsuccessfully, so that any changes or effects that the transaction may have applied to the database must be undone.
In addition to the preceding operations, some recovery techniques require additional operations that include the following:
- UNDO: Similar to rollback, except that it applies to a single operation rather than to a whole transaction.
- REDO: This specifies that certain transaction operations must be redone to ensure that all the operations of a committed transaction have been applied successfully to the database.
A state transaction diagram is shown below:
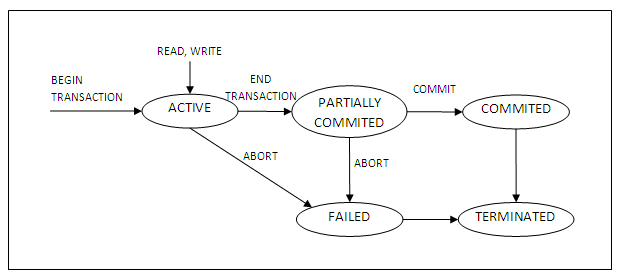
Figure 13.1
It shows clearly how a transaction moves through its execution states. In the diagram, circles depict a particular state; for example, the state where a transaction has become active. Lines with arrows between circles indicate transitions or changes between states; for example, read and write, which correspond to computer processing of the transaction.
A transaction goes into an active state immediately after it starts execution, where it can issue read and write operations. When the transaction ends, it moves to the partially committed state. At this point, some concurrency control techniques require that certain checks be made to ensure that the transaction did not interfere with other executing transactions. In addition, some recovery protocols are needed to ensure that a system failure will not result in inability to record the changes of the transaction permanently. Once both checks are successful, the transaction is said to have reached its commit point and enters the committed state. Once a transaction enters the committed state, it has concluded its execution successfully.
However, a transaction can go to the failed state if one of the checks fails or if it aborted during its active state. The transaction may then have to be rolled back to undo the effect of its write operations on the database. The terminated state corresponds to the transaction leaving the system. Failed or aborted transactions may be restarted later, either automatically or after being resubmitted, as brand new transactions.
Interleaved concurrency
Many computer systems, including DBMSs, are used simultaneously by more than one user. This means the computer runs multiple transactions (programs) at the same time. For example, an airline reservations system is used by hundreds of travel agents and reservation clerks concurrently. Systems in banks, insurance agencies, stock exchanges and the like are also operated by many users who submit transactions concurrently to the system. If, as is often the case, there is only one CPU, then only one program can be processed at a time. To avoid excessive delays, concurrent systems execute some commands from one program (transaction), then suspended that program and execute some commands from the next program, and so on. A program is resumed at the point where it was suspended when it gets its turn to use the CPU again. This is known as interleaving.
The figure below shows two programs A and B executing concurrently in an interleaved fashion. Interleaving keeps the CPU busy when an executing program requires an input or output (I/O) operation, such as reading a block of data from disk. The CPU is switched to execute another program rather than remaining idle during I/O time.
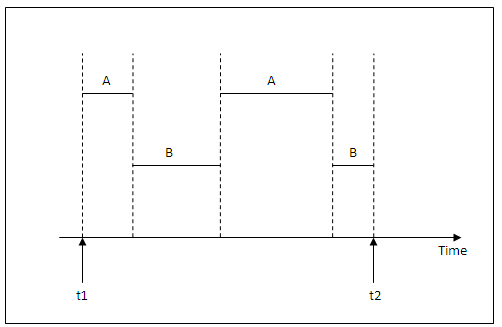
Figure 13.2
Interleaved vs simultaneous concurrency
If the computer system has multiple hardware processors (CPUs), simultaneous processing of multiple programs is possible, leading to simultaneous rather than interleaved concurrency, as illustrated by program C and D in the figure below. Most of the theory concerning concurrency control in databases is developed in terms of interleaved concurrency, although it may be adapted to simultaneous concurrency.
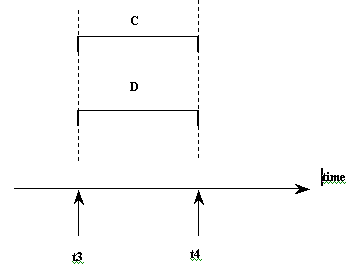
Figure 13.3
Genuine vs appearance of concurrency
Concurrency is the ability of the database management system to process more than one transaction at a time. You should distinguish genuine concurrency from the appearance of concurrency. The database management system may queue transactions and process them in sequence. To the users it will appear to be concurrent but for the database management system it is nothing of the kind. This is discussed under serialisation below.
Read and write operations
We deal with transactions at the level of data items and disk blocks for the purpose of discussing concurrency control and recovery techniques. At this level, the database access operations that a transaction can include are:
- read_item(X): Reads a database item named X into a program variable also named X.
- write_item(X): Writes the value of program variable X into the database item named X.
Executing a read_item(X) command includes the following steps:
- Find the address of the disk block that contains item X.
- Copy the disk block into a buffer in main memory if that disk is not already in some main memory buffer.
- Copy item X from the buffer to the program variable named X.
Executing a write_item(X) command includes the following steps:
- Find the address of the disk block that contains item X.
- Copy the disk block into a buffer in main memory if that disk is not already in some main memory buffer.
- Copy item X from the program variable named X into its correct location in the buffer.
- Store the updated block from the buffer back to disk (either immediately or at some later point in time).
Step 4 is the one that actually updates the database on disk. In some cases the buffer is not immediately stored to disk, in case additional changes are to be made to the buffer. Usually, the decision about when to store back a modified disk block that is in a main memory buffer is handled by the recovery manager or the operating system.
A transaction will include read and write operations to access the database. The figure below shows examples of two very simple transactions. Concurrency control and recovery mechanisms are mainly concerned with the database access commands in a transaction.

Figure 13.4
The above two transactions submitted by any two different users may be executed concurrently and may access and update the same database items (e.g. X). If this concurrent execution is uncontrolled, it may lead to problems such as an inconsistent database. Some of the problems that may occur when concurrent transactions execute in an uncontrolled manner are discussed in the next section.
Activity 1 - Looking up glossary entries
In the Concurrent Access to Data section of this chapter, the following phrases have glossary entries:
- transaction
- interleaving
- COMMIT
- ROLLBACK
- In your own words, write a short definition for each of these terms.
- Look up and make notes of the definition of each term in the module glossary.
- Identify (and correct) any important conceptual differences between your definition and the glossary entry.
Review question 1
- Explain what is meant by a transaction. Discuss the meaning of transaction states and operations.
- In your own words, write the key feature(s) that would distinguish an interleaved concurrency from a simultaneous concurrency.
- Use an example to illustrate your point(s) given in 2.
- Discuss the actions taken by the read_item and write_item operations on a database.
Need for concurrency control
Concurrency is the ability of the DBMS to process more than one transaction at a time. This section briefly overviews several problems that can occur when concurrent transactions execute in an uncontrolled manner. Concrete examples are given to illustrate the problems in details. The related activities and learning tasks that follow give you a chance to evaluate the extent of your understanding of the problems. An important learning objective for this section of the chapter is to understand the different types of problems of concurrent executions in OLTP, and appreciate the need for concurrency control.
We illustrate some of the problems by referring to a simple airline reservation database in which each record is stored for each airline flight. Each record includes the number of reserved seats on that flight as a named data item, among other information. Recall the two transactions T1 and T2 introduced previously:
Figure 13.5
Transaction T1 cancels N reservations from one flight, whose number of reserved seats is stored in the database item named X, and reserves the same number of seats on another flight, whose number of reserved seats is stored in the database item named Y. A simpler transaction T2 just reserves M seats on the first flight referenced in transaction T1. To simplify the example, the additional portions of the transactions are not shown, such as checking whether a flight has enough seats available before reserving additional seats.
When an airline reservation database program is written, it has the flight numbers, their dates and the number of seats available for booking as parameters; hence, the same program can be used to execute many transactions, each with different flights and number of seats to be booked. For concurrency control purposes, a transaction is a particular execution of a program on a specific date, flight and number of seats. The transactions T1 and T2 are specific executions of the programs that refer to the specific flights whose numbers of seats are stored in data item X and Y in the database. Now let’s discuss the types of problems we may encounter with these two transactions.
The lost update problem
The lost update problem occurs when two transactions that access the same database items have their operations interleaved in a way that makes the value of some database item incorrect. That is, interleaved use of the same data item would cause some problems when an update operation from one transaction overwrites another update from a second transaction.
An example will explain the problem clearly. Suppose the two transactions T1 and T2 introduced previously are submitted at approximately the same time. It is possible when two travel agency staff help customers to book their flights at more or less the same time from a different or the same office. Suppose that their operations are interleaved by the operating system as shown in the figure below:
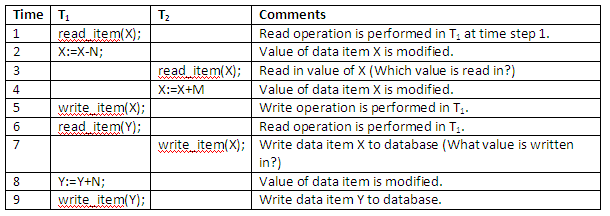
Figure 13.6
The above interleaved operation will lead to an incorrect value for data item X, because at time step 3, T2 reads in the original value of X which is before T1 changes it in the database, and hence the updated value resulting from T1 is lost. For example, if X = 80, originally there were 80 reservations on the flight, N = 5, T1 cancels 5 seats on the flight corresponding to X and reserves them on the flight corresponding to Y, and M = 4, T2 reserves 4 seats on X.
The final result should be X = 80 – 5 + 4 = 79; but in the concurrent operations of the figure above, it is X = 84 because the update that cancelled 5 seats in T1 was lost.
The detailed value updating in the flight reservation database in the above example is shown below:
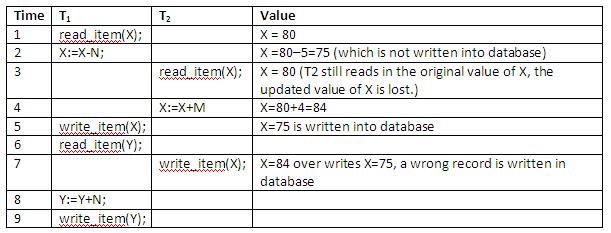
Figure 13.7
Uncommitted dependency (or dirty read / temporary update)
Uncommitted dependency occurs when a transaction is allowed to retrieve or (worse) update a record that has been updated by another transaction, but which has not yet been committed by that other transaction. Because it has not yet been committed, there is always a possibility that it will never be committed but rather rolled back, in which case, the first transaction will have used some data that is now incorrect - a dirty read for the first transaction.
The figure below shows an example where T1 updates item X and then fails before completion, so the system must change X back to its original value. Before it can do so, however, transaction T2 reads the 'temporary' value of X, which will not be recorded permanently in the database because of the failure of T1. The value of item X that is read by T2 is called dirty data, because it has been created by a transaction that has not been completed and committed yet; hence this problem is also known as the dirty read problem. Since the dirty data read in by T2 is only a temporary value of X, the problem is sometimes called temporary update too.

Figure 13.8
The rollback of transaction T1 may be due to a system crash, and transaction T2 may already have terminated by that time, in which case the crash would not cause a rollback to be issued for T2. The following situation is even more unacceptable:

Figure 13.9
In the above example, not only does transaction T2 becomes dependent on an uncommitted change at time step 6, but it also loses an update at time step 7, because the rollback in T1 causes data item X to be restored to its value before time step 1.
Inconsistent analysis
Inconsistent analysis occurs when a transaction reads several values, but a second transaction updates some of these values during the execution of the first. This problem is significant, for example, if one transaction is calculating an aggregate summary function on a number of records while other transactions are updating some of these records. The aggregate function may calculate some values before they are updated and others after they are updated. This causes an inconsistency.
For example, suppose that a transaction T3 is calculating the total number of reservations on all the flights; meanwhile, transaction T1 is executing. If the interleaving of operations shown below occurs, the result of T3 will be off by amount N, because T3 reads the value of X after N seats have been subtracted from it, but reads the value of Y before those N seats have been added to it.

No comments:
Post a Comment